 In the career of a professional developer there is a time where we are asked not only to produce high quality software but also to become a leader for our team. And this new task requires different skills in order to be achieved, being a leader is not easy and it can definitely be frightening.
In the career of a professional developer there is a time where we are asked not only to produce high quality software but also to become a leader for our team. And this new task requires different skills in order to be achieved, being a leader is not easy and it can definitely be frightening.
In this blog post I will not share my experience regarding this topic. Why? Simply because, when writing these lines, I am not a software team leader. And therefore I cannot give you tips for an experience I have not yet lived.
This article will be about a book that shares the experience of an actual team leader: Roy Osherove. In his book, “Notes to a Software Team Leader“, Roy explains the concept of the elastic leadership and also what are the 3 phases in which a software development team can be.
Why did I read this book?
You might wonder why I read this book about software leadership since I am not a team leader. And I asked myself the same question before reading the book. Well, maybe one day I will be asked to take the role of a leader in a software development team.
I am the kind of person who likes to plan ahead and therefore I decided to read this book about the responsibilities I might have one day. By doing so I will be able to have ideas about what will await me for this challenge.
Also, the two senior developers of my team read the book and they referred to its content. They spoke about comfort zone, commitment language and others topics. And it made me curious, so I decided to read the book to able to understand what they were talking about. And after doing it I was able to understand a bit more their situation and mine as well in the team.
In some software development teams there is no formal team leader, there are only programmers which have to work with each others in order to complete the tasks they have. And sometimes you are the most experienced developer of the team in the company and even if you did not ask for it, you are kind of the leader.
I went through short periods like these ones during my career and it can be stressful because you just don’t know how to behave when facing some situations. Reading the book can be helpful to understand in which phase you currently are and how to get out of it.
Elastic Leadership
The “ultimate” style of leadership just does not exist. If it does we would all know it by now. To be an effective leader you will have to adapt to the context you are working in, the work environment, the personalities within the team and everything that can have an impact on your team. Your leadership has to be “elastic” and you have to adapt it depending on the situation.
In “Notes to a Software Team Leader”, Roy Osherove describes 3 different kinds of leadership: command-and-control leadership, coaching leadership and facilitating leadership.
In a command-and-control mode, the team leader tries to solve everyone’s problem. This looks commendable for your team but it can also prevents your team members to learn anything since you are doing all the work.
The “coach” leader is great at teaching new things to others. He will let you experienced new things and sometimes let you do some mistakes if there are lessons to learn. This mode is helpful for your team but in some situations you can’t do it because your don’t have time for it, there are too many fires to put out.
The facilitator leader stays out-of-the-way. He makes sure that the environment is optimal for its team and relies on the skills on the team members to get things done. This type of leadership cannot be achieved if the developers are not experienced enough to face the challenges they have to deal with.
These three leadership styles can be applied to different phases that a team can encountered during the lifetime of a project.
Survival phase
Does your team spend its days on putting out fires? There is absolutely no time for learning new technologies and technics? Then you probably are in the survival mode.
Even if does not look like the kind of environment you want for your team it can be appealing to stay in it. Why? Because day after day you will do the same kind of work, the kind of work that feel “safe” because you have already done it, several times. You are in your comfort zone even if there are fires everyday.
To get out of this phase, you have to break the circle by providing slack time dedicated to learning. By gaining new skills the team members will be able to deal with more issues they have to face.
For example they can learn about refactoring technics in order to decrease the technical debt of the project. They can learn how to add unit tests to the source code.
You should not see these learning opportunities as a waste of time but as an investment in your team.
The survival phase is the time where command-and-control management can be helpful. You take control of the ship to avoid sinking and you give orders. To correct previously made bad decisions, to avoid mistakes you know will happen. Your job is to get the team out of the survival mode, to aim for the learning phase.
Learning phase
In this phase, the focus is on gaining new skills. The project is more stable than it was during survival phase and you now have time to spend on improving things.
You are no longer needed to apply a command-and-control type of management, you now need to act as a coach. Helping your coworkers to learn is your goal.
When learning you are not increasing your productivity at a constant rate, the curve is more like the one shown on the graph below.
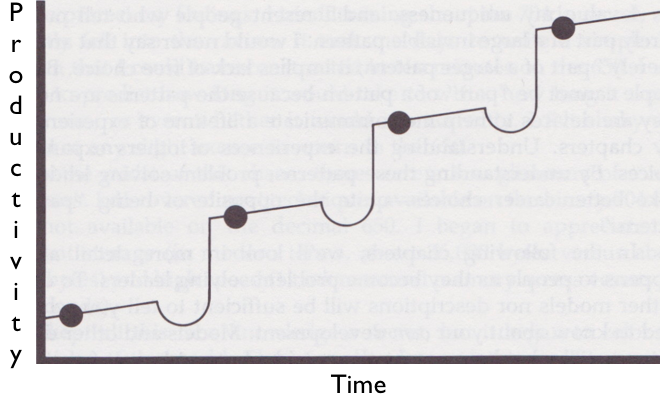
There are ravines before each peak, they are adjustment phases and they might seem painful because your productivity is decreasing. Yet you should embrace them because they are leading you to new paradigms, skills and knowledge, you are stepping outside of your comfort zone.
The learning phase is the perfect time to teach about commitment language. When you will do something, you mean it and you will actually do it! I wrote an article about “saying yes” a while back, where it is all about commitment.
You also have to teach your team to start dealing with its own problems, the one you were dealing with during the previous phase. When a new issue is raised by a member of your team you should give them the following answer: “What will you do about it?“.
This question aims to make the members take actions in order to deal with the challenges they are facing everyday. And they of course have to answer the question using commitment language.
But what if the solution is not in our hands? Then in which hands is it? What prevents you from speaking to this person/team to explain your issue?
Even if in a lot of situations we cannot fix our problems alone, this does not mean that we are powerless. There is always an action that can be done by ourself to get closer to the “fixed” state for our issue.
During the learning phase, the team leader has to focus on the autonomy of its team to make it self-organized.
Self organization phase
When the team enters the self-organization phase, you can follow the facilitating kind of leadership. You act as a guide and remind your team the concept they learned during the learning phase, such as the commitment language.
You do not have much to do, you give your teams goals and after that you just get out of their way. They should know how to deal with the challenges they will face. They will learn the skills they need in order to get things done.
During this phase there is not much else for you to do.
Conclusion
As a software team leader, I think that your job is to strive to create self-organized teams. In a way you have to make yourself “unnecessary” by making your team autonomous. Don’t worry, this is a long and fastidious work so you won’t be unemployed just after a few months. And when you reach this goal, you can take another team stuck in the survival phase and grow the people working in it. There are a lot of software development teams that need your help!
This is just an overview of the book content and I can only encourage you to read it to learn more. I think that it is not only intended to be read by team leaders but also by every professional programmers who is interested by the phases a software development team can be in.
See you next time!



















