
Several months ago I introduced the concept of mocking dependencies of a class in order to ease the writing of tests for it. I also introduced the Moq library which is a mocking library and today I will introduced another one: NSubstitute. This project is open source and you can find it on GitHub.
I will not cover all the functionalities it offers, instead I will show you how it works with an example like I did with Moq. First you can install NSubstitute with Nuget:
Install-Package NSubstitute
What to test?
I have created the following service with a bit of logic to test.
public class NotificationService { public NotificationService(IUserRepository userRepository, INotifier notifier, ILogger logger) { _userRepository = userRepository; _notifier = notifier; _logger = logger; } private readonly IUserRepository _userRepository; private readonly INotifier _notifier; private readonly ILogger _logger; public void NotifyUser(int userId) { User user; try { user = _userRepository.GetById(userId); } catch (Exception ex) { _logger.Error(ex.Message); return; } if (user.HasActivatedNotification) { _notifier.Notify(user); } } }
This service relies on dependency injection to do its work, you’ll find these dependencies below.
public interface INotifier { void Notify(User user); } public interface IUserRepository { User GetById(int userId); } public interface ILogger { void Error(string message); } public class User { public bool HasActivatedNotification { get; set; } } public class InvalidUserIdException : Exception { public override string Message { get { return "Given user ID is invalid"; } } }
Let’s test it!
I will now write tests to cover the logic hold by the NotificationService class using NSubstitute. I will also use xUnit as testing framework, you can find more information about this project here.
In order to test the service we will have to instantiate it, and therefore we will have to inject the dependencies. So the first question is: how to create mock (or substitute) with NSubstitute? As a reminder it is done like this with Moq:
Mock<IUserRepository> mockRepository = new Mock<IUserRepository>(); IUserRepository repo = mockRepository.Object;
With NSubstitute the concept is similar but with one noticeable change.
IUserRepository userRepository = Substitute.For<IUserRepository>();
There is no wrapper for the mock, we directly manipulate an instance of the interface we want to substitute. You might wonder how to use it as a mock if it has only the methods defined in the interface, I’ll come to that later.
We can now setup our test class for the service with all the dependencies.
public class NotificationService_Should { private readonly NotificationService _service; private readonly IUserRepository _userRepository; private readonly INotifier _notifier; private readonly ILogger _logger; public NotificationService_Should() { _userRepository = Substitute.For<IUserRepository>(); _notifier = Substitute.For<INotifier>(); _logger = Substitute.For<ILogger>(); _service = new NotificationService(); } }
For information, the test setup is done in the class constructor with xUnit.
We can now focus on writing the first test for the class: verifying that the repository is called when executing the NotifyUser method. To do so we will use some extension methods provided by NSubstitute (here is the answer to the previous question).
[Fact(DisplayName = "NotifyUser calls the repository")] public void Call_Repository() { _service.NotifyUser(Arg.Any<int>()); _userRepository.Received().GetById(Arg.Any<int>()); }
The Received() extension method checks that the following method is called. Since we don’t have to test for a particular user ID, we can use the Arg.Any<T>() method to specify that any integer is valid (with Moq it is It.IsAny<T>()). We run the test and…
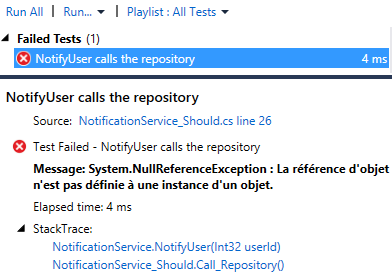
…it’s red? NullReferenceException… Of course! The mock repository does not return any instance of User and the execution fails after when trying to use the reference. Let’s fix this by configuring the substitute.
[Fact(DisplayName = "NotifyUser calls the repository")] public void Call_Repository() { _userRepository.GetById(Arg.Any<int>()).Returns(new User()); _service.NotifyUser(1); _userRepository.Received().GetById(Arg.Any<int>()); }
Now the test is green, but in this test we setup a mock and then we test that it has been called, in my opinion it is not very constructive. We should try to focus on testing something else, the rest of the method’s logic depends on a property of the User, let’s test this for instance.
public NotificationService_Should() { _userRepository = Substitute.For<IUserRepository>(); _notifier = Substitute.For<INotifier>(); _logger = Substitute.For<ILogger>(); _service = new NotificationService(_userRepository, _notifier, _logger); _userRepository .GetById(Arg.Is<int>(i => i < 10)) .Returns(new User { HasActivatedNotification = true }); _userRepository .GetById(Arg.Is<int>(i => i >= 10)) .Returns(new User { HasActivatedNotification = false }); } [Fact(DisplayName = "NotifyUser calls notifier if user has activated the notifications")] public void Call_Notifier_When_User_Has_Activated_Notification() { _service.NotifyUser(1); _notifier.Received().Notify(Arg.Any<User>()); } [Fact(DisplayName = "NotifyUser does not call notifier if user has not activated the notifications")] public void Does_Not_Call_Notifier_When_User_Has_Not_Activated_Notification() { _service.NotifyUser(11); _notifier.DidNotReceive().Notify(Arg.Any<User>()); }
This time I used the Arg.Is<T>() method to add condition to the substitute, this way I can setup the result of a method depending on some conditions. Here I set the HasActivatedNotification property to true if the userId is inferior to 10 and to false otherwise.
And to test that a method is not called I use the DidNotReceive() extension method. Now I will write a test for the case when an exception is thrown by the repository to check that the logger is correctly called.
public NotificationService_Should() { _userRepository = Substitute.For<IUserRepository>(); _notifier = Substitute.For<INotifier>(); _logger = Substitute.For<ILogger>(); _service = new NotificationService(_userRepository, _notifier, _logger); _userRepository .GetById(Arg.Is<int>(i => i < 10)) .Returns(new User { HasActivatedNotification = true }); _userRepository .GetById(Arg.Is<int>(i => i >= 10)) .Returns(new User { HasActivatedNotification = false }); _userRepository .GetById(Arg.Is<int>(i => i < 0)) .Returns(user => { throw new InvalidUserIdException(); }); } [Fact(DisplayName = "NotifyUser calls logger when an exception is thrown")] public void Call_Logger_When_An_Exception_Is_Thrown() { _service.NotifyUser(-1); _logger.Received().Error("Given user ID is invalid"); }
The service is now covered with tests thanks to the use of NSubstitute.

This library offers more functionalities, you can find them on the documentation page of the project website.
As for me, I only discovered this library recently, I am more used to Moq. But I must say that I like the API offered by NSubstitute, I find it more “fluent”. I think it can be really helpful when doing Test Driven Development (TDD). I will definitely give it a shot for future projects.
Choosing a mocking library is important in order to write tests easily when using dependency injection and there is a lot of choice for this, Moq and NSubstitute are some of them. And you? What is your favorite library for mocking? What does it offer that others don’t have?
See you next time!









