A few weeks ago I shared my experience of moving from web development to mobile development. In this article I mentioned asynchronous programming which is mandatory for desktop and mobile applications.
A few weeks ago I shared my experience of moving from web development to mobile development. In this article I mentioned asynchronous programming which is mandatory for desktop and mobile applications.
Today I will give you an example to demonstrate how to use the async-await pattern in order to avoid having a User Interface (UI) that freezes (does not respond to user interaction).
The synchronous approach
In this demo, I have created a simple WPF application with a button and a label, I will not use the Model-View-ViewModel (MVVM) pattern in this example. When clicking on the button some data will be retrieved on a repository and processed by a service before updating the label with the value.

Here is the XAML for this window:
<Window x:Class="AsyncAwait.WPF.MainWindow" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" xmlns:d="http://schemas.microsoft.com/expression/blend/2008" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:local="clr-namespace:AsyncAwait.WPF" mc:Ignorable="d" Title="MainWindow" Height="350" Width="525"> <Grid> <Button x:Name="button" Content="Button" HorizontalAlignment="Left" Margin="10,10,0,0" VerticalAlignment="Top" Width="497" Click="button_Click"/> <Label x:Name="label" Content="Label" HorizontalAlignment="Left" Margin="10,45,0,0" VerticalAlignment="Top" Width="497"/> </Grid> </Window>
And the C# code can be found below.
// MainWindow.xaml.cs public partial class MainWindow : Window { public MainWindow() { _domainService = new DomainService(); InitializeComponent(); } private readonly DomainService _domainService; private void button_Click(object sender, RoutedEventArgs e) { var labelData = _domainService.GetData(); this.label.Content = labelData; } } // DomainService.cs public class DomainService { public DomainService() { _dataRepository = new DataRepository(); } private readonly DataRepository _dataRepository; public string GetData() { var data = _dataRepository.RetrieveData(); data = ComputeData(data); return data; } private string ComputeData(string data) { Thread.Sleep(5000); // mocking calculation latency return data.ToUpper(); } } // DataRepository.cs public class DataRepository { public string RetrieveData() { return RetrieveDataInternal(); } private string RetrieveDataInternal() { Thread.Sleep(5000); // mocking latency return "my data"; } }
I used the Thread.Sleep() method to mock latency, due to database/network access and calculation time.
From a syntax point of view the code compile and does what it needs to do. But when we launch this program, the UI will freeze for 10 seconds and will not respond to the user interactions. This clearly not the best experience for a software.
The application has this behavior because all the work is done on the UI thread and it won’t be able to do its main work: displaying and refreshing the UI (responding to the user inputs is part of it).
It is time to update the code to make the code asynchronous.
Using Async-Await
I refactored the previous code to be able to use the async and await keywords.
// MainWindow.xaml.cs public partial class MainWindow : Window { public MainWindow() { _domainService = new DomainService(); InitializeComponent(); } private readonly DomainService _domainService; private async void button_Click(object sender, RoutedEventArgs e) { try { var labelData = await _domainService.GetDataAsync(); this.label.Content = labelData; } catch (Exception ex) { MessageBox.Show(ex.Message); } } } // DomainService.cs public class DomainService { public DomainService() { _dataRepository = new DataRepository(); } private readonly DataRepository _dataRepository; public async Task<string> GetDataAsync() { var data = await _dataRepository.RetrieveDataAsync(); data = ComputeData(data); return data; } private string ComputeData(string data) { Thread.Sleep(5000); // mocking calculation latency return data.ToUpper(); } } // DataRepository.cs public class DataRepository { public Task<string> RetrieveDataAsync() { return RetrieveDataInternalAsync(); } private Task<string> RetrieveDataInternalAsync() { Thread.Sleep(5000); return Task.FromResult("my data"); } }
Great! It should be better this way, let’s try it… It still freeze for 10 seconds… Even with the async-await pattern!
That is normal, the program does not create a Task on a separate thread and therefore all the code is still executed on the UI thread. Only using the async/await keywords is not enough to make the code asynchronous. Some methods of the .NET framework will create tasks on separate thread to allow you to use this pattern, like the GetAsync() method of the HttpClient class (see more examples here). You can detect them by looking at the “Async” suffix in the method name, it is a convention to use this suffix to notify calling code that the method is “awaitable”.
In my case I will fix my problem by creating a new Task with the Task.Run() method:
// DataRepository.cs private Task<string> RetrieveDataInternalAsync() { return Task.Run(() => { Thread.Sleep(5000); // mocking latency return "my data"; }); }
This gives me a Task I can use in my class hierarchy to run the code asynchronously. Now if we run the program it is better but the UI will still freeze for about 5 seconds…
This is caused by the ComputeData() method in the DomainService class which is executed on the UI thread. Well, I can use another Task.Run() to solve this problem. True but I can also use another feature of the Task to solve my issue: Task.ConfigureAwait():
// DomainService.cs public async Task<string> GetDataAsync() { var data = await _dataRepository.RetrieveDataAsync().ConfigureAwait(false); data = ComputeData(data); return data; }
The parameter of the ConfigureAwait method (named “continueOnCaptureContext”) allows us to specify if we want that the rest of the method to executed on the captured context or not. This refers to the calling thread which is the UI thread in my case. By default this value is set to true and that means that the ComputeData() method was executed on the UI thread which explains why the application froze.
Now, if we run the application, the label will still be updated after 10 seconds but the Window will be responding to the user interactions which is, in my opinion way better for the user experience.
This ConfigureAwait tip looks great, let me use it on the button_Click() method!
// MainWindow.xaml.cs private async void button_Click(object sender, RoutedEventArgs e) { try { var labelData = await _domainService.GetDataAsync().ConfigureAwait(false); this.label.Content = labelData; } catch (Exception ex) { MessageBox.Show(ex.Message); } }
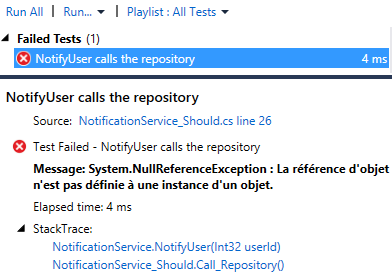
But when I run the program, I have the following result:

I have an InvalidOperationException with the following message: “The calling thread cannot access this object because a different thread owns it”, displayed in a message box (in French in my case due to my configuration).
This error happens because I try to access the label property of the MainWindow from a thread different from the UI one. This is caused by the ConfigureAwait(false) I put, in this case I don’t want it because the code needs to be executed on the captured context.
Conclusion
Working with the async/await pattern needs practice to be understood, I wrote this article to explains some concepts of it by showing its impacts on a UI interface. I do not claim to be an expert on the subject, there is a lot more I need to learn on this topic. But remember that you need a Task to work with to unlock the potential of this pattern.
The Task.ConfigureAwait() method is also a powerful ally to lighten the work done by the UI thread but it needs to be used carefully to avoid invalid operations in the application.
The async keywork can only be used on methods returning a Task, a Task<T>, or void. This last case can be dangerous and should be avoided as much as possible, in my case the only async void method is the button_click event handler. I took care of encapsulating the whole code in a try/catch block and every time you see an async void method you should do it as well. Because it behaves as a “fire and forget” call and if you do not handle the exceptions in the method, they will be raise later without knowing exactly when or where and it will likely stop the process and the application.
I hope this example can help you if you are starting with asynchronous programming in C# .NET.
See you next time!
Image credits: